Tuning Engines
The unified, governed runtime that lets you control every AI interaction through one API with zero markup on infrastructure.
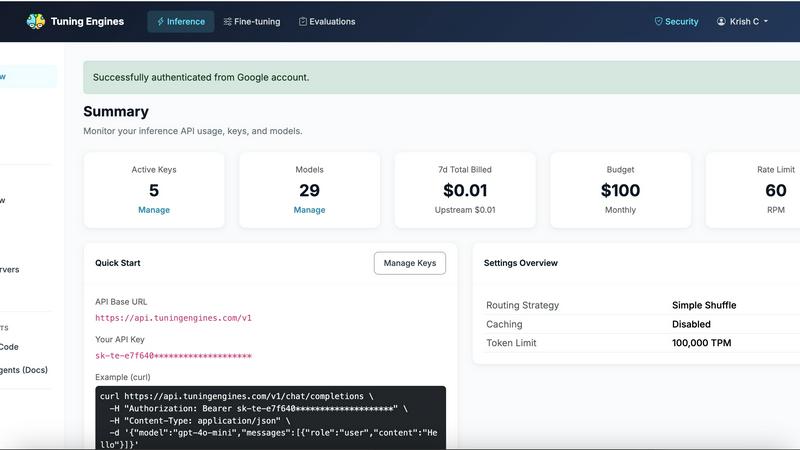
About Tuning Engines
Tuning Engines is a unified AI control and governance layer from CerebrixOS that acts as a universal intelligence runtime for teams building production-grade AI systems. It is designed to help organizations move beyond isolated AI experiments into a secure, observable, cost-aware, and extensible operating layer where models can be trained, evaluated, routed, governed, and used by agents and tools at scale. The platform brings together the full AI lifecycle in one governed platform, covering inference, model routing, fallback policies, fine-tuning jobs, datasets, evaluations, model imports and exports, custom models, agents, MCP servers, reusable skills, guardrails, AGT YAML policies, data capture, runtime traces, usage analytics, API keys, billing, team roles, and integrations. Developers get OpenAI-compatible APIs, Anthropic-compatible routes, CLI workflows, MCP access, coding-agent integrations, and resource catalogs for models, agents, tools, and skills. Teams can connect Claude Code, OpenCode, Aider, Cline, Roo, Continue.dev, Cursor, VS Code, Windsurf, and other AI workflows through a single governed platform. Admins get the controls needed for production including role-based access, per-key budgets, rate limits, routing profiles, fallback rules, guardrails, policy-as-code, credential sources, auditability, usage traces, billing controls, tenant isolation, and team management. Backed by Google Cloud for Startups, NVIDIA Inception, Rogers Cybercatalyst, ElevenLabs Grants, AWS Activate, and BDC Capital, Tuning Engines offers a unique infrastructure cost model where compute costs are passed through at-cost with zero markup, so you only pay for support and platform upkeep.
Features of Tuning Engines
Unified Inference API
One OpenAI-compatible endpoint that works with your existing SDK. Just swap the base URL and call any open, frontier, or tuned model. No code rewrites, no new client to learn. The platform supports over 100 models including Llama 3.3 70B, DeepSeek V3, DeepSeek R1, Qwen 2.5 72B, Mistral Small 3, Mixtral 8x7B, Gemma 2 27B, Llama 3.2 Vision, Whisper Large v3, and Embeddings from the BGE and E5 family. Plus commercial frontier models and any model you fine-tune with the platform, all behind the same endpoint with streaming and structured output support.
Model Tuning and Lifecycle
Adapt open models to your data, language, and tasks with supervised fine-tuning and LoRA adapters. The platform handles the entire model lifecycle from build to tune to scale. Run the fastest inference, tune with your data, and host your own models without managing GPU infrastructure. Evaluation gates ensure quality moves with your business, so you can ship with evidence and confidence.
Centralized Policy and Governance
Apply centralized guardrails, access controls, and full request traceability across every model. Admins can set role-based access, per-key budgets, rate limits, routing profiles, fallback rules, guardrails, policy-as-code with AGT YAML, credential sources, and auditability. Token economics keep spend and rate limits predictable with cost ceilings, quotas, routing, and fallbacks.
Agent and Tool Integration
Connect Claude Code, OpenCode, Aider, Cline, Roo, Continue.dev, Cursor, VS Code, Windsurf, and other AI workflows through a single governed platform. The platform supports MCP servers, reusable skills, agentic systems with multi-step reasoning, planning, and tool-using execution pipelines. Developers get CLI workflows, MCP access, coding-agent integrations, and resource catalogs for models, agents, tools, and skills.
Use Cases of Tuning Engines
Code Assistance
Build IDE copilots, code generation, refactoring, and debugging agents that operate through a single governed API. Teams can connect their favorite coding tools like Cursor, VS Code, Windsurf, and Continue.dev to access models with centralized policy control, auditability, and token economics. Developers get the speed of direct model access with the safety of enterprise governance.
Conversational AI
Deploy customer support bots, internal helpdesks, and multilingual chat systems that use any model from the library. With fallback policies and routing profiles, you can ensure uptime and quality even when one model goes down. Guardrails and policy controls keep conversations safe and compliant, while usage analytics give you full visibility into costs and performance.
Agentic Systems
Build multi-step reasoning, planning, and tool-using execution pipelines that can call models, tools, and skills through the same governed platform. Agents can be configured with MCP servers, reusable skills, and AGT YAML policies so they operate within defined boundaries. Runtime traces provide full auditability of every agent action and decision.
Enterprise RAG
Implement secure, scalable retrieval over knowledge bases and private documents using the platform's embedding models and LLMs. With tenant isolation, role-based access, and credential sources, you can build retrieval-augmented generation systems that keep enterprise data safe. Token economics and per-key budgets ensure predictable costs even at scale.
Frequently Asked Questions
How does the unified API work with my existing code?
You keep your existing OpenAI SDK and simply swap the base URL to https://api.tuningengines.com/v1. No code rewrites, no new client to learn. The API is fully OpenAI-compatible, so you can call any open, commercial, or tuned model with the same interface. Streaming, structured output, and all standard parameters work exactly as expected.
What models are available on the platform?
The model library includes popular open weight models like Llama 3.3 70B, Llama 3.1 8B, DeepSeek V3, DeepSeek R1, Qwen 2.5 72B, Qwen 2.5 Coder 32B, Mistral Small 3, Mixtral 8x7B, Gemma 2 27B, Llama 3.2 Vision, Whisper Large v3, and Embeddings from the BGE and E5 family. Plus commercial frontier models and any model you fine-tune with the platform, all behind the same endpoint.
How does pricing work for infrastructure?
Infrastructure costs are passed through at-cost with zero markup. You only pay Tuning Engines for support and platform upkeep. This means you get enterprise-grade governance and tooling without the typical cloud markup on compute. Token economics with cost ceilings, quotas, routing, and fallbacks help keep spend and rate limits predictable.
How do I connect my existing coding tools?
You can connect Claude Code, OpenCode, Aider, Cline, Roo, Continue.dev, Cursor, VS Code, Windsurf, and other AI workflows through a single governed platform. The platform provides OpenAI-compatible APIs, Anthropic-compatible routes, CLI workflows, MCP access, and coding-agent integrations. Just configure your tool with the Tuning Engines endpoint and API key.
Similar to Tuning Engines
AIQualityHQ
AIQualityHQ is a free local engine that instantly scores and sharpens your prompts across six key dimensions for safer, smarter AI outputs.
CreatorlaneHQ
CreatorlaneHQ is the all-in-one Instagram toolkit that auto-DMs leads and sells your storefront products.
EchoLeads AI
EchoLeads AI unleashes hyper-realistic voice agents that cold call, qualify leads, and book appointments on autopilot without human fatigue.
Xposto
Xposto automates X posting and smart replies from your docs and feeds to grow impressions and monetization fast.
Skygen AI
Skygen AI is your hyper-productive AI wingman that crushes workflows, builds agents, and handles tasks so you don't have to.
HyperLake
HyperLake delivers sovereign AI infrastructure with zero compute markup, empowering agents to explore and innovate without limits.
Decker
Decker is the OS that turns messy drafts into board-ready deliverables and pays you when your work trains the AI.